

21 jul Wat is het crawlbudget?
Auteur: Erwan Vrignaud
Leestijd: 18 minuten
Het crawlbudget is een concept dat vaak wordt besproken in SEO- en digitale marketinggesprekken maar ook vaak verkeerd wordt begrepen. Veel mensen hebben de neiging om te denken dat het iets is wat je met technieken kunt “manipuleren” om zo hoog in de SERP (Search Engine Result Page) terecht te komen. Deze aanname is volkomen onjuist. Ondanks dat je zelf wel enige invloed uit kunt oefenen is het uitgangspunt ook verkeerd. Wanneer je alle regels volgt om een zo relevante en gebruikersvriendelijk mogelijke website te maken hoef je je niet druk te maken over het crawlbudget. Maar wat houdt het nou precies in en hoe werkt het?
In dit artikel zal ik de basisprincipes van crawlen beschrijven en hoe je deze kunt gebruiken om te bepalen of het ‘crawlbudget’ iets is waar je je druk om moet maken en of het echt iets belangrijks is voor jouw website.
De volgende punten komen aan bod:
• Hoe zoekmachines werken (een korte introductie).
• Hoe verloopt het crawlproces?
• Wat is het crawlbudget?
• Hoe werkt het crawlbudget?
• De Crawlvraag
• Hoe controleer ik het crawlproces?
• Het crawlbudget optimaliseren.
• Hoe het crawlproces is veranderd
• De toekomst van crawlen.
Voordat we dieper ingaan op het concept van crawlbudget en de implicaties ervan, is het belangrijk om te begrijpen hoe het crawlproces werkt en wat het betekent voor de zoekmachines.
Hoe zoekmachines werken
Volgens Google zijn er drie basisstappen die de zoekmachine volgt om resultaten van webpagina’s te genereren:
• Crawlen : webcrawlers hebben toegang tot openbaar beschikbare webpagina’s.
• Indexering : Google analyseert de content van elke pagina en slaat de gevonden informatie op.
• Weergave (en rangschikking): wanneer een gebruiker een zoekopdracht typt, presenteert Google de meest relevante antwoorden uit zijn index.
Hoe verloopt het crawlproces?
• Crawlers gebruiken links op sites om andere pagina’s te ontdekken. (De interne linkstructuur van jouw site is cruciaal.)
• Crawlers geven prioriteit aan nieuwe sites, wijzigingen aan bestaande sites en dode links.
• Een geautomatiseerd proces bepaalt welke sites moeten worden gecrawld, hoe vaak en hoeveel pagina’s Google zal ophalen.
• Het crawlproces wordt beïnvloed door de hostingmogelijkheden (serverbronnen en bandbreedte).
Het doorzoeken van het web is een ingewikkeld en duur proces voor zoekmachines, gezien de grootte van het web. Zonder een effectief crawlproces is Google niet in staat om alle informatie van het web te ordenen en universeel toegankelijk te maken. Maar hoe garandeert Google effectief crawlen? Door prioriteit te geven aan pagina’s en bronnen. Het zal voor Google bijna onmogelijk en duur zijn om elke afzonderlijke webpagina te crawlen.
Wat is het crawlbudget?
Het crawlbudget is het aantal pagina’s dat een crawler instelt om in een bepaalde periode te crawlen. Zodra jouw budget is opgebruikt, stopt de webcrawler met het openen van content van jouw site en gaat hij verder naar andere sites. Crawlbudgetten zijn voor elke website anders en het crawlbudget van jouw site wordt automatisch vastgesteld door Google. De zoekmachine gebruikt een groot aantal factoren om te bepalen hoeveel budget aan jouw site wordt toegewezen. Over het algemeen zijn dit de vier belangrijkste factoren die Google gebruikt om het crawlbudget toe te wijzen:
• Sitegrootte : voor grotere sites is meer crawlbudget nodig.
• Serverconfiguratie : de prestaties en laadtijden van jouw site kunnen van invloed zijn op het budget dat eraan wordt toegewezen.
• Updatefrequentie: hoe vaak werk je jouw content bij? Google geeft prioriteit aan content die regelmatig wordt bijgewerkt.
• Links : Interne linkstructuur en dode links.
Hoewel het waar is dat crawlgerelateerde problemen Google kunnen verhinderen toegang te krijgen tot de meest kritieke content van jouw site, is het belangrijk om te begrijpen dat de crawlfrequentie geen kwaliteitsindicator is. Als je site vaker wordt gecrawld, zul je niet per se beter scoren. Als jouw content niet voldoet aan de verwachtingen van jouw doelgroep zal deze geen nieuwe bezoekers aantrekken. Dit gaat niet veranderen door de Googlebot jouw site vaker te laten crawlen.
Hoe werkt het crawlbudget?
Het crawlbudget is een concept waar in de regel door de meeste website-eigenaren geen zorgen over hoeft te worden gemaakt Als een site minder dan een paar duizend URL’s heeft dan worden deze meestal allemaal efficiënt gecrawld. Google weet dat zijn bot ernstige beperkingen kan opleggen aan websites als het niet voorzichtig te werk zou gaan, dus ze hebben controlemechanismen om te garanderen dat hun crawlers een website slechts zo vaak bezoeken als voor die site noodzakelijk is om geen hinder te veroorzaken. De limiet voor de crawlsnelheid helpt Google bij het bepalen van het crawlbudget voor een website.
In het kort werkt het als volgt:
• Googlebot crawlt een website.
• De bot zal de server van de site pushen en kijken hoe deze reageert.
• Googlebot zal dan de limiet verlagen of verhogen.
In Search Console van Google is het mogelijk de Crawlstatistieken te bekijken. Deze informatie vind je bij de Instellingen terug.
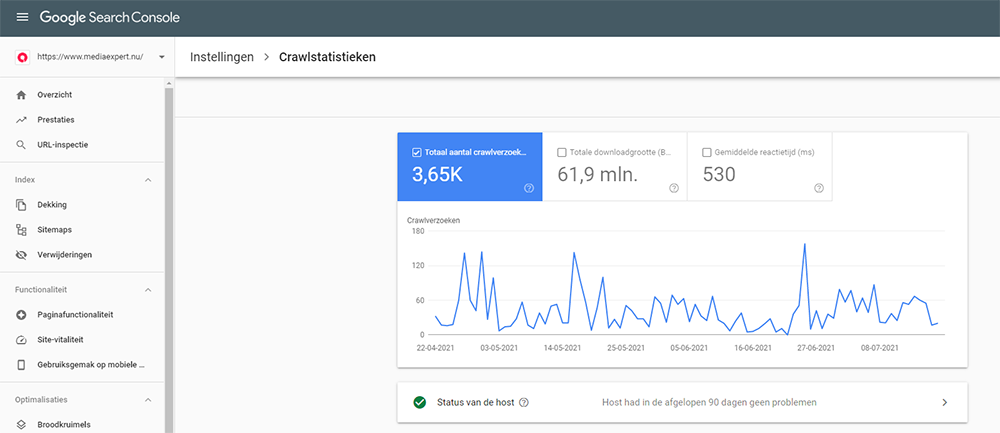
In Google Search Console kun je de crawlstatistieken opvragen
De Crawlvraag
De twee factoren die een belangrijke rol spelen bij het bepalen van de crawlvraag zijn:
• URL-populariteit: populaire pagina’s worden vaker geïndexeerd dan pagina’s die dat niet zijn.
• Verouderd: het systeem van Google voorkomt verouderde URL’s en geeft voorrang aan up-to-date content.
Google gebruikt deze limieten voor crawlsnelheid en crawlvraag voornamelijk om het aantal URL’s te bepalen dat Googlebot kan en wil crawlen (crawlbudget). Factoren die van invloed zijn op het crawlbudget. Als je een aanzienlijk aantal URL’s met lage relevantiewaarde op jouw site hebt, kan dit de crawlbaarheid van jouw site negatief beïnvloeden. Zaken zoals oneindig scrollen, dubbele content en spam zullen het crawlpotentieel van jouw site aanzienlijk verminderen. Hier volgt een lijst met kritieke factoren die van invloed zijn op het crawlbudget van jouw site:
• Server- en hostingconfiguratie
• Google houdt rekening met de stabiliteit van elke website.
• Googlebot zal niet continu een site crawlen die constant crasht.
Als jouw website veel dynamische pagina’s heeft, kan dit problemen met dynamische URL’s en toegankelijkheid veroorzaken. Door deze problemen kan Google niet meer pagina’s op jouw website indexeren. Waar je ook waakzaam voor moet zijn is dubbele content. Duplicatie kan een groot probleem zijn, omdat het geen meerwaarde biedt voor Google-gebruikers. Ook content van lage kwaliteit is een groot gevaar. De crawler verlaagt ook jouw budget als hij ziet dat een aanzienlijk deel van de content op jouw website van lage kwaliteit of zelfs spam is.
Hoe controleer ik het crawlproces?
Het kan moeilijk zijn om erachter te komen en te controleren wat jouw huidige crawlbudget is, aangezien de nieuwe Search Console de meeste verouderde rapporten verbergt. Het bijhouden van serverlogboeken klinkt technisch maar geeft wel het beste beeld. In serverlogboeken wordt elk verzoek aan jouw webserver opgeslagen. Elke keer dat een gebruiker of Googlebot jouw site bezoekt, wordt er een logboekitem toegevoegd aan het toegangslogbestand. Googlebot laat een vermelding achter in jouw toegangslogbestand wanneer deze jouw website bezoekt. Je kunt dit logbestand handmatig of automatisch analyseren om te zien hoe vaak Googlebot naar jouw website komt. Er zijn commerciële log-analysers (Screaming Frog) die dit kunnen doen, ze helpen je relevante informatie te krijgen over wat Google-bot op jouw website doet.
Analyserapporten van serverlogboeken laten het volgende zien:
• Hoe vaak jouw site wordt gecrawld.
• Welke pagina’s wordt door de Googlebot het meest bezocht.
• Welk type fouten de bot is tegengekomen.
Het crawlbudget optimaliseren?
Het optimaliseren van het crawlbudget is alleen een optie om te overwegen bij grote websites. Los daarvan is het voor elke website raadzaam prioriteit te geven aan pagina’s die echte waarde bieden aan jouw eindgebruiker. Pagina’s die klikken en inkomsten genereren moeten gemakkelijk toegankelijk zijn voor crawlers. Soms is het een goed idee om een individuele XML-sitemap te maken met jouw belangrijkste pagina’s. Download jouw serverlogbestanden om patronen en mogelijke problemen te identificeren en een idee te krijgen van hoe jouw huidige serverconfiguratie wordt beïnvloed door Googlebot.Maak meerdere sitemaps gecategoriseerd op URL-type of sectie binnen jouw site (bijvoorbeeld products.xml, blog-post.xml, enz.). Dit zal helpen het crawlproces naar de meest waardevolle secties op jouw site te controleren. Ruim jouw website op door slechte content, dubbele content en/of spam te verwijderen. Ook blijven links van pagina naar pagina nog steeds uiterst belangrijk voor het crawlproces. Elke website moet periodiek gecontroleerd worden op zaken zoals verkeerde omleidingen, 404 meldingen en mogelijke andere fouten. Je kunt jouw robots.txt-bestand optimaliseren door niet-waardevolle URL’s of bestanden (zoals garantievoorwaarden, inlogschermen, disclamers, etc.) uit te sluiten van het crawlproces. Wees wel secuur in dit proces want mocht er een belangrijk CSS-bestand worden geblokkeerd om een belangrijke pagina weer te geven, dan zal Google deze ook niet lezen.
Hoe het crawlproces is veranderd
Google en het crawlproces zijn in de loop van de tijd geëvolueerd. In maart 2018 begon Google prioriteit te geven aan mobiele content op het web en het actualiseren van haar index van desktop-first naar mobile-first. Dit is besloten nadat duidelijk werd dat er steeds meer websites door mobiele apparaten werden bezocht en de prognoses zijn dat mobiel zelfs desktop in zal gaan halen. Als ze dat niet al gedaan hebben. Ik zie maar al te vaak bij klanten van mij dat hun website tegenwoordig vaker door mobiele gebruikers wordt bezocht dan door de desktopgebruikers. Vroeger was het regel dat mobiel meer oriënterend verkeerd was en desktop converterend, maar ook dit lijkt achterhaald. Bij sommige van mijn klanten met mobielvriendelijke webshops zie ik dat er bijvoorbeeld 80% van de aankopen door mobiel wordt gedaan tegen 15% op desktop en 5% op tablet. Niet vreemd dat Google dus de mobiele versie van een website het eerst crawlt. Met deze verschuiving werd Google’s Desktop Bot vervangen door de smartphone Googlebot als de belangrijkste crawler.
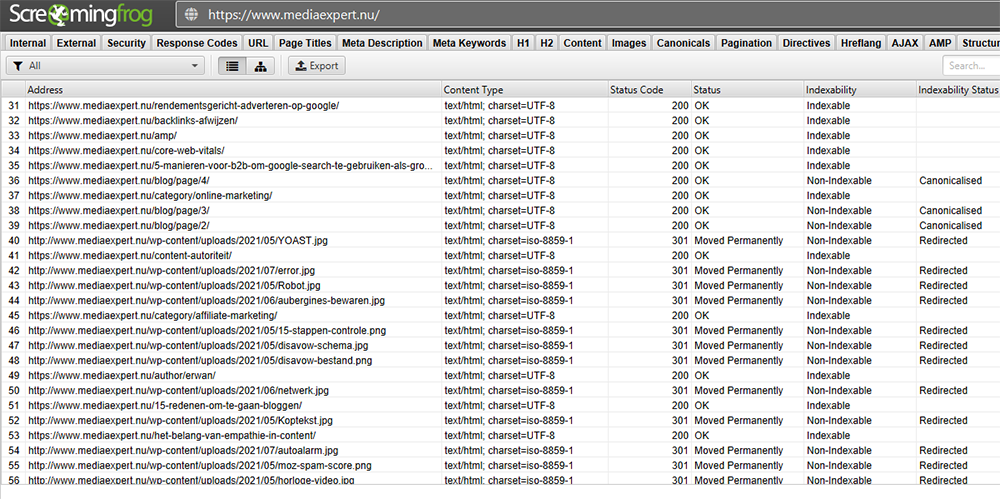
Met Screaming Frog kun je controleren hoe Google de pagina’s van jouw website leest
De toekomst van crawlen
De manier waarop Google het web crawlt is constant in ontwikkeling. Een belangrijk element wat steeds zwaarder mee zal gaan wegen is machine learning, oftewel AI (Artificial Intelligence) genoemd. Google Zoeken maakt bijvoorbeeld al gebruik van BERT (hou je vast: Bidirectional Encoder Representations from Transformers) om het begrip van menselijke taal, rangschikkingsalgoritmen en pagina’s met zoekresultaten te ondersteunen en te verbeteren. Door zware investeringen in machine learning en AI-programma’s kan Google een beter voorspellingsmodel krijgen voor sterk gepersonaliseerde pagina’s met zoekresultaten. In Google Ads zien we dit ook terug in de Dynamische Advertenties die in mijn ogen een groot succes zijn. De advertentieteksten worden volledig aangepast aan de zoekwoorden en zoekintentie van de gebruiker en sluit daardoor vaak veel beter aan dan wanneer alles handmatig is ingesteld. Menselijke interactie blijft noodzakelijk omdat ook Google uiteraard niet alles weet, maar het conversiepercentage van dit soort advertenties ligt vaak hoger dan bij de standaard advertenties. En precies dit soort algoritmes zijn ook van toepassing om de organische resultaten samen te stellen en soms verbaast het mij dat als ik een, in mijn ogen, niet hele specifieke vraag stel in de Google zoekbalk er een antwoord komt wat nauw aansluit op wat ik wilde weten. Het is het proces van de toekomst, Google gaat niet voor ons denken, maar helpt ons met denken. Maar het wordt steeds moeilijker om het web te doorzoeken. Met bijna 2 miljard websites op internet is het crawlen en indexeren van content een uitdagend en duur proces geworden voor Google. Als het web in dit tempo blijft groeien, zal het voor Google gemakkelijker zijn om alleen het indexerings- en rangschikkingsproces te controleren. Het weigeren van pagina’s met spam of pagina’s van lage kwaliteit zal het crawlproces aanzienlijk efficiënter maken. In de toekomst zal Google zeer waarschijnlijk de omvang van zijn index verkleinen om prioriteit te geven aan kwaliteit en ervoor te zorgen dat de resultaten relevant en nuttig zijn.
Conclusie
Crawlbudget – als concept en potentiële optimalisatiestatistiek – is relevant en nuttig voor een specifiek type website. In de regel hele grote websites. Door Google te helpen het crawlproces sneller en efficiënter te voltooien zal dit ook een groot voordeel opleveren voor de eigenaar van de website zelf. Een zeer grote website met bijvoorbeeld tiendduizenden (of meer) pagina’s waar het merendeel bestaat uit verouderde en niet relevante content, loopt kans steeds minder vaak en grondig door Google bezocht te worden. Als je iedere week een rommelmarkt bezoekt en het begint steeds meer op een vuilnisbelt te lijken, dan loop je een volgende keer ook liever door. Een betere metafoor kan ik niet bedenken. In de toekomst kan het idee van een crawlbudget veranderen of zelfs helemaal verdwijnen, aangezien Google voortdurend evolueert en nieuwe oplossingen voor zijn gebruikers test. Heb je een website met niet meer dan een paar duizend pagina’s? Dan is de conclusie vrij simpel: blijf vasthouden aan de basisprincipes en geef prioriteit aan activiteiten die toegevoegde waarde creëert voor jouw doelgroep. Zorg dat alles tiptop in orde is, zowel technisch als inhoudelijk. Google ziet dit en beloont dit. Heb je hier hulp of advies bij nodig? Neem contact op!